线粒体单倍群性别构成比例的差异性研究
时值岁尾,正逢新春,作为庚子年内祖源公众号的最后一次例行推文,咱们一不写寻亲,二不写民族,三不写寻宗,四不写家族,既不促销卖货,也不引流吸粉,笔者准备专心致志地写一篇关于线粒体单倍群的专(y-o-n-g)业(s-u)性研究。
这一切源自于笔者的一个偶发灵感,笔者在整理家族树的时候,偶然发现有这样一些「超级外婆」或「超级祖母」现象的存在。就是有一些女性,如果她在整个生育期内所生育的女儿数量远远大于儿子数量的时候;或者她在整个生育期内所生育的儿子数量远远大于女儿数量的时候,那么这个现象在她的女儿身上也往往也会重现。
这个现象是个例还是普遍存在?
若存在的话能够占到所有女性多大的比例?
能不能用有效的手段去揭示这些问题?
笔者也曾经在社区做过一轮家系调查,如果只是进行家系例举汇集的话,这个方法显然不够高效,也无法获得这个群体的整体轮廓。
这种「超级外婆」或「超级祖母」代际传递的特征只局限于传递给其女儿,这似乎和线粒体的母系遗传特征相吻合。这样笔者就顺利地把「超级外婆」或「超级祖母」的社会现象,转化成了一个「线粒体单倍群性别构成比例差异性问题」的研究。于是笔者设计了如下的统计方案进行研究。
统计口径:23魔方祖源数据库内填写了「性别」及「籍贯」信息的所有样本。
数据清洗和基线均衡化方法:
第一步,排除掉数据库中有晚近亲缘关系的样本:统计数据库中所有样本的基因关系,如果出现 2-3 级基因关系对的,随机保存其中的 1 个样本作为代表。
第二步,性别基线均衡化:以地级市为统计单位,统计经过第一步清洗以后的各地区的男女数量,并以该地区性别最少的人数为基准,对该地区的「异性样本集」进行相同样本数量的随机化抽样,由此而组建该地区的「异性样本集」。
「性别基线均衡化方法」的举例说明:假设经过第一步排除晚近亲缘样本后,成都市还有300 个样本,其中女性 165 人,男性 135 人。我们以性别最少的男性 135 人为基准,对 165 名成都女性样本进行随机化抽样,由此而获得了成都市经过性别基线均衡化后的 270 人的数据集。由此遍历全国各个地区,最终汇集成全国的数据集。
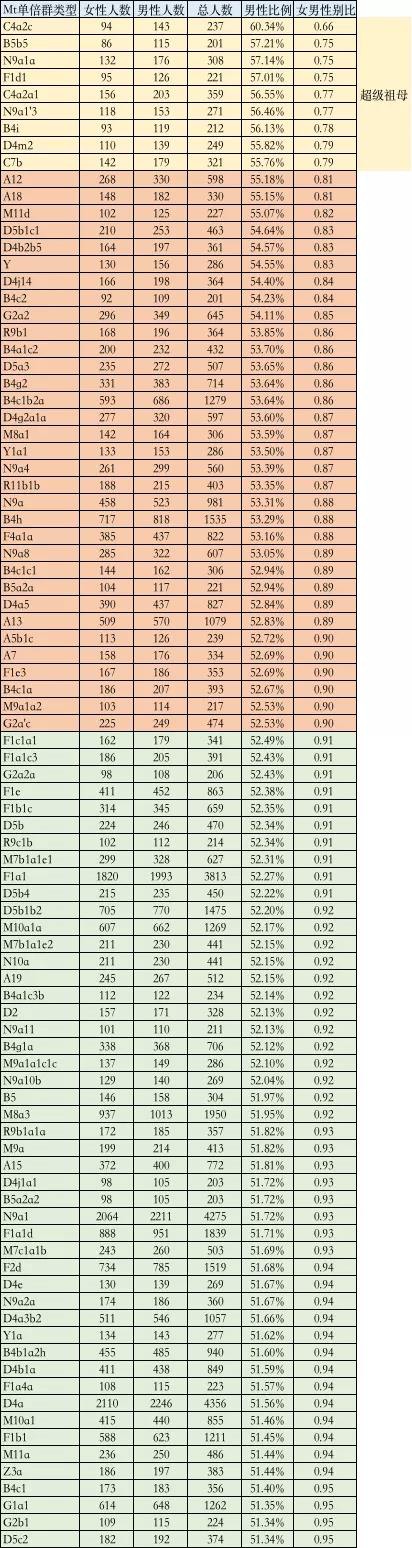
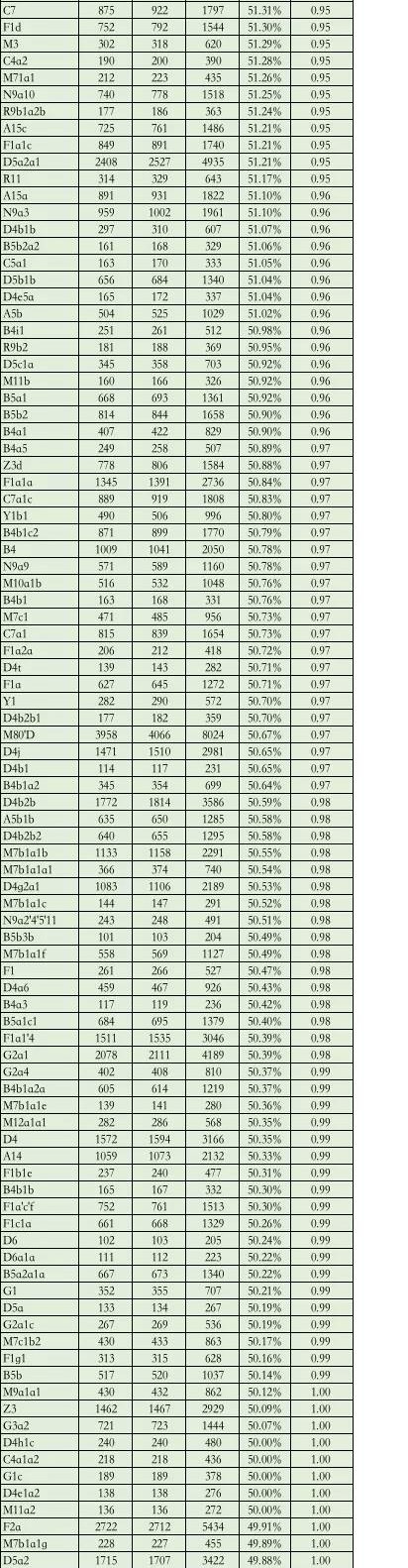
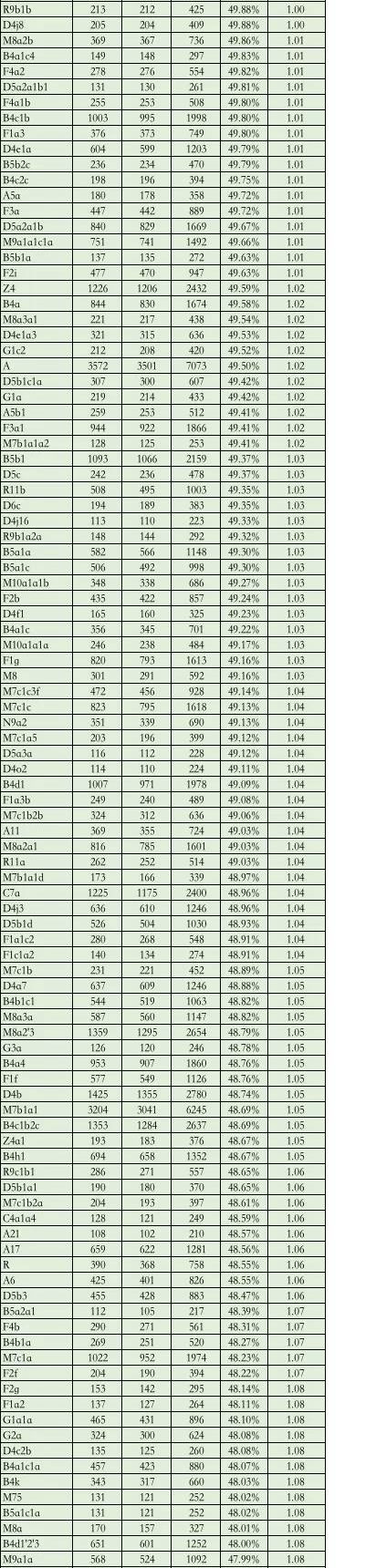
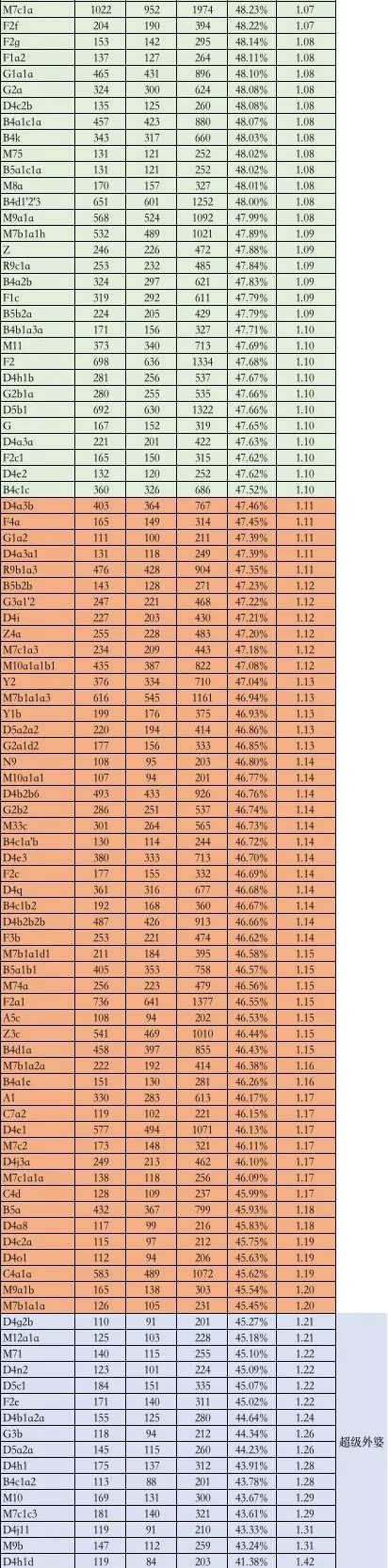
第三步,统计全国数据集中各线粒体单倍群的男女人数及比例。为了防止小样本量造成的干扰,最后去掉总样本数小于 200 人的线粒体单倍群的统计结果。
经过上述方法统计后,共有 368 个线粒体单倍群类型的 316185 名样本进入了统计,结果发现:
· 有 70.65% 的线粒体单倍群女男性别比(女性数量除以男性数量)在 0.9~1.1 之间,男女相对均衡的占据了大多数;
· 有 14.13% 的线粒体单倍群女男性别比在 1.1~1.2 之间;
· 有 8.42% 的线粒体单倍群女男性别比在 0.8~0.9 之间;
· 有 2.45% 的线粒体单倍群女男性别比小于 0.8;
· 有 4.35% 的线粒体单倍群女男性别比大于 1.2。
其中女男性别比小于 0.8 的线粒体单倍群可能对应到我所观察到的「超级祖母」的类型;女男性别比大于 1.2 的线粒体单倍群则可能对应了「超级外婆」类型。
其中有意思的是「超级外婆」类型无论是单倍群数量还是人数都是远大于「超级祖母」类型的,背后的原因可能与这两类线粒体单倍群各自不同的繁衍路线相关。
「超级祖母」的类型因为繁衍路线的高度非利己特征(即生育的女儿数量越少,越不利于该单倍群的繁衍),势必会导致自身的逐步萎缩。「超级外婆」虽然走的是优先利己的繁衍路线,人群理应会越来越大,但是也可能存在一些非生物性的回归因素。比如历史上长期存在的抚育性别筛选、性别歧视等因素都可能造成这些「超级外婆」类型的保育存活的女儿数量与生育性别均衡的女性相比并无太大优势。
当然进入到了新时代新时期,随着女性整体社会地位的提升、生育少子化等新的社会特征出现,上述现象将逐渐消失。
下面我们逐一介绍这些「超级外婆」类型和「超级祖母」类型的分布特征:
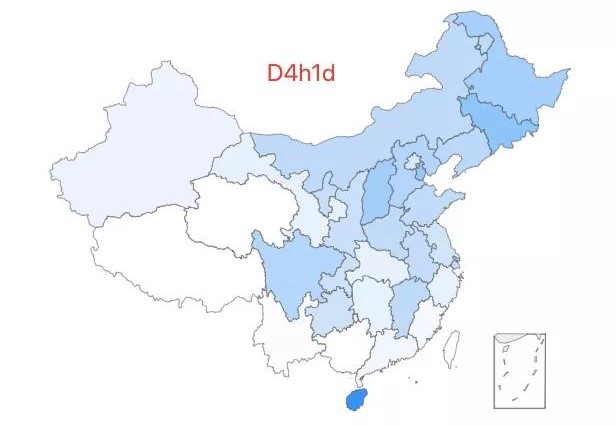
1.「超级外婆 1 号」——D4h1d 类型,该类型约占中国人口的 0.06%,主要分布在北方,在海南有一个蛙跳式的高频分布地(小样本)。
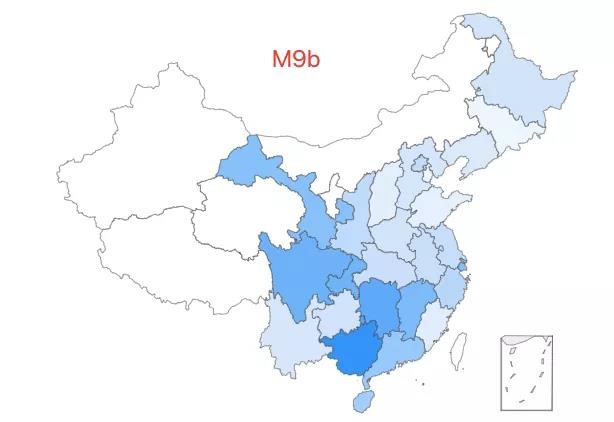
 2.「超级外婆 2 号」——M9b 类型,该类型约占中国人口的 0.08%,主要分布在广西、湖南、江西、川渝等中西南地域,在甘肃也有较高分布。
2.「超级外婆 2 号」——M9b 类型,该类型约占中国人口的 0.08%,主要分布在广西、湖南、江西、川渝等中西南地域,在甘肃也有较高分布。
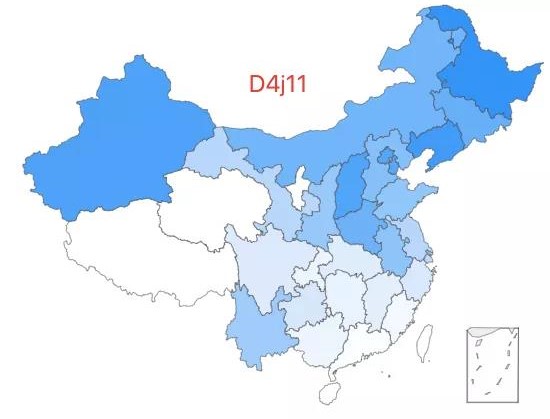
3.「超级外婆 3 号」——D4j11 类型,该类型约占中国人口的 0.06%,主要分布在东北、华北及西北等地。
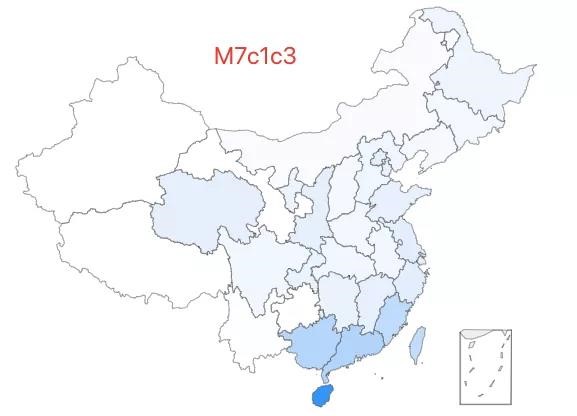
4.「超级外婆 4 号」——M7c1c3 类型,该类型约占中国人口的 0.01%,主要分布在华南等地,在广泛的北方也有零星的分布。
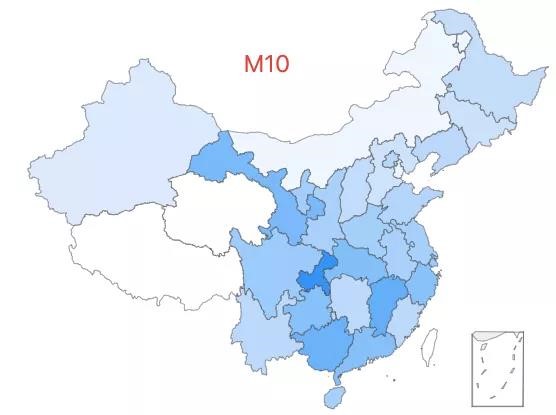
5.「超级外婆 5 号」——M10 类型,该类型约占中国人口的 0.09%,全国广泛分布。
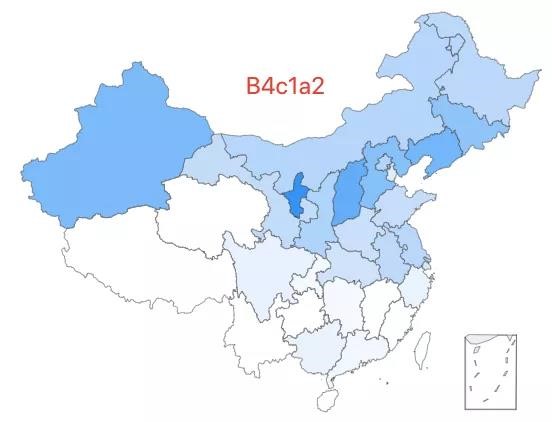
6.「超级外婆6号」——B4c1a2 类型,该类型约占中国人口的 0.06%,主要分布在长江以北等地。
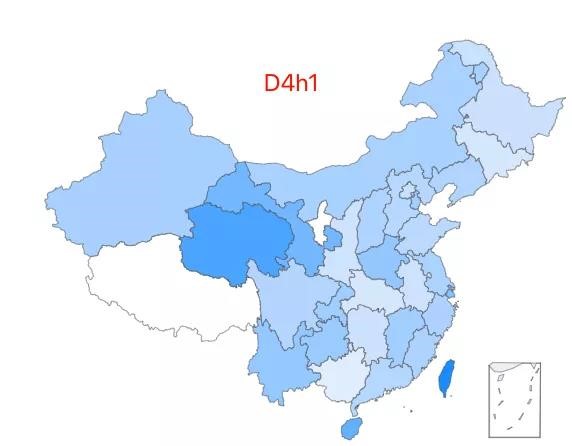
7.「超级外婆 7 号」——D4h1 类型,该类型约占中国人口的 0.09%,全国广泛分布。
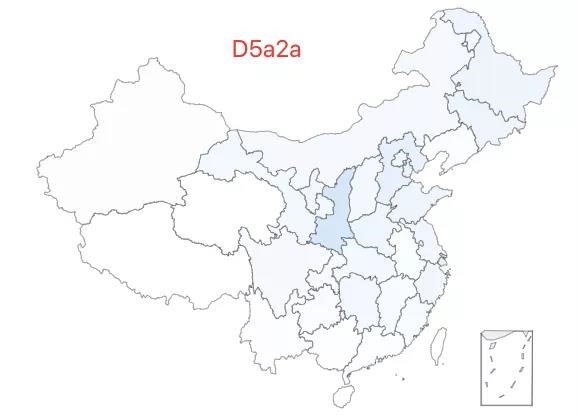
8.「超级外婆 8 号」——D5a2a 类型,该类型约占中国人口的 0.06%,全国广泛分布。
9.「超级外婆 9 号」——G3b 类型,该类型约占中国人口的 0.07%,全国广泛分布,在西藏有较高比例。
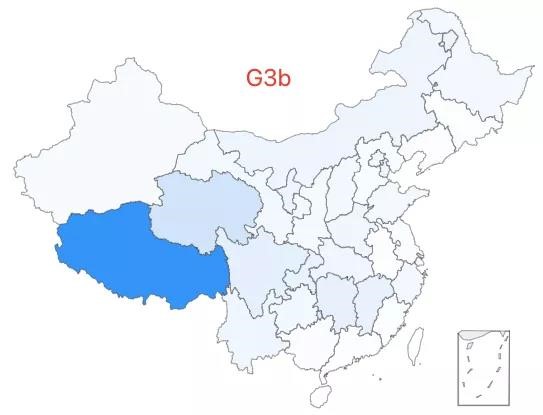
10.「超级外婆 10 号」——D4b1a2a 类型,该类型约占中国人口的 0.07%,全国广泛分布,在北方相对聚集。
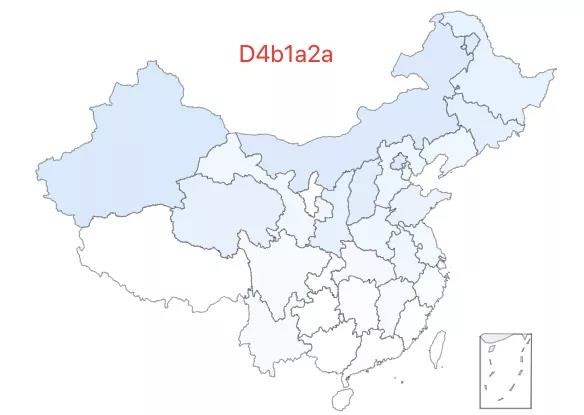
11.「超级外婆 11 号」——F2e 类型,该类型约占中国人口的 0.10%,全国广泛分布,在海南有较高比例。
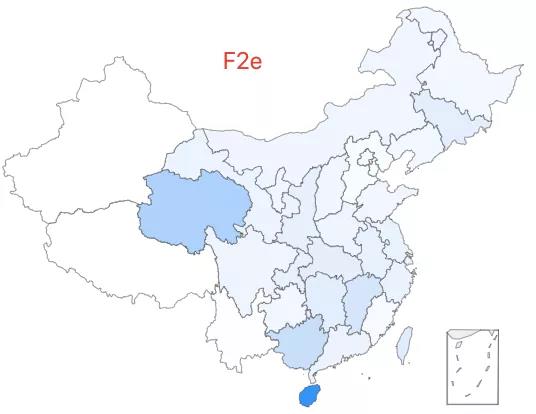
12.「超级外婆 12 号」——D5c1 类型,该类型约占中国人口的 0.09%,全国广泛分布。
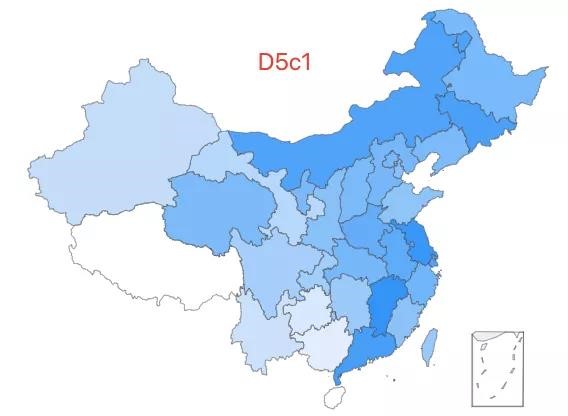
13.「超级外婆 13 号」——D4n2 类型,该类型约占中国人口的 0.06%,全国广泛分布,华北、西北相对高频。
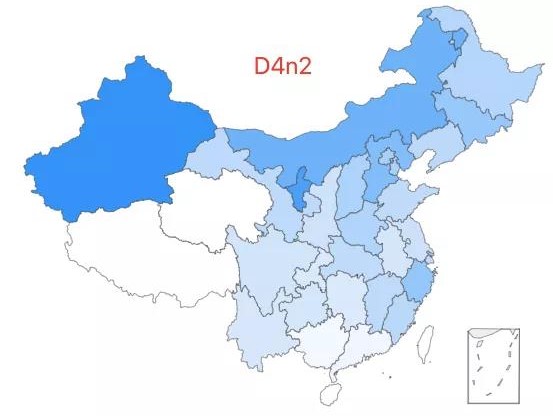
14.「超级外婆 14 号」——M71 类型,该类型约占中国人口的 0.08%,全国广泛分布,西南相对高频。
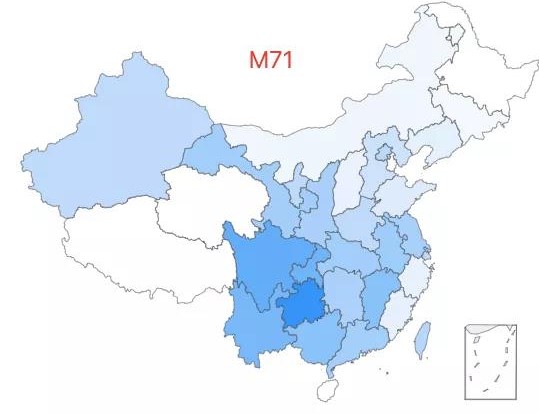
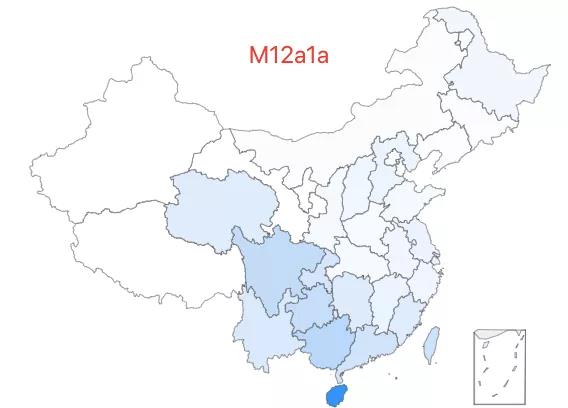
15.「超级外婆 15 号」——M12a1a 类型,该类型约占中国人口的 0.07%,主要西南、中南等地。
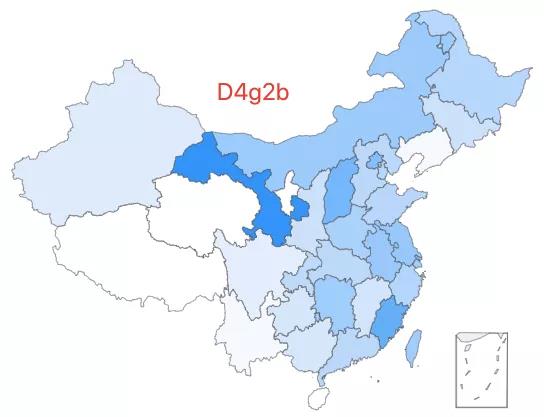
16.「超级外婆 16 号」——D4g2b 类型,该类型约占中国人口的 0.05%,全国广泛分布,在甘肃有较高比例。
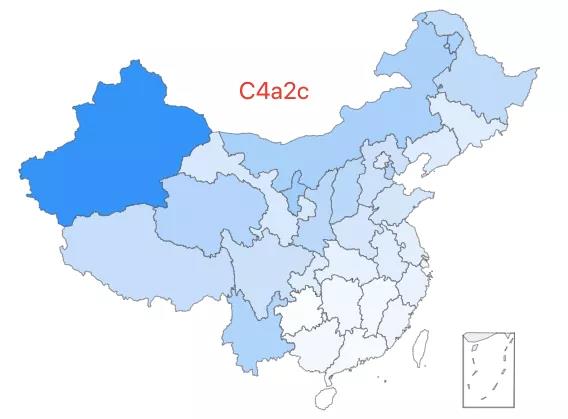
17.「超级祖母 1 号」——C4a2c 类型,该类型约占中国人口的 0.07%,相对高频的分布于胡焕庸线以西的广大区域内。
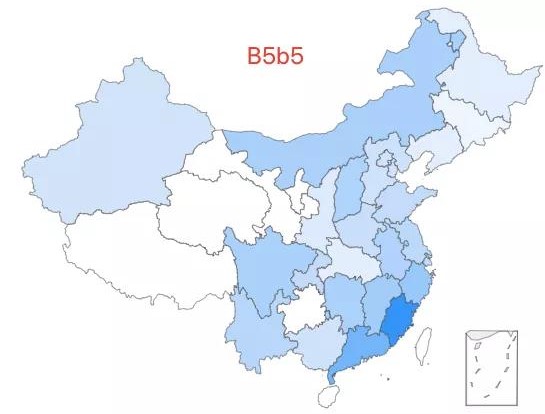
18.「超级祖母 2 号」——B5b5 类型,该类型约占中国人口的 0.05%,全国广泛分布,在福建有较高比例。
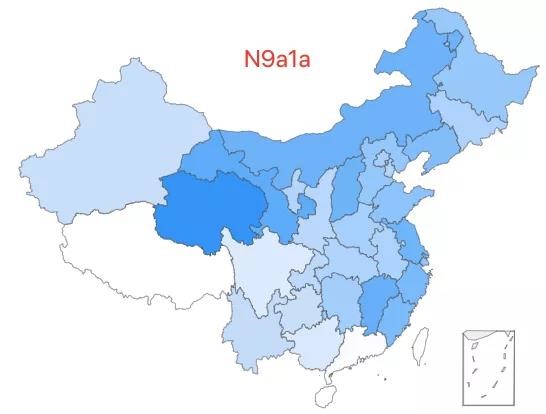
19.「超级祖母 3 号」——N9a1a 类型,该类型约占中国人口的 0.08%,全国广泛分布,在西北和东南地区较高比例。
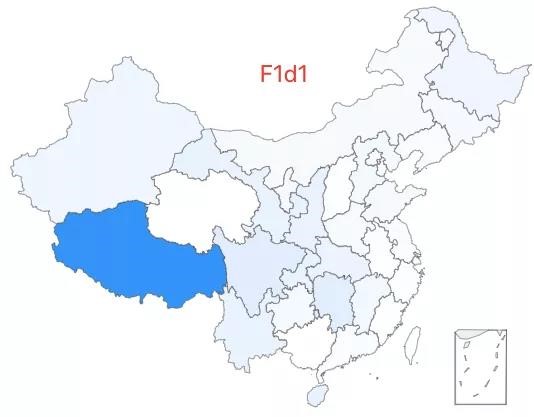
20.「超级祖母 4 号」——F1d1 类型,该类型约占中国人口的 0.08%,全国广泛分布,在西部及西藏有相对较高比例。
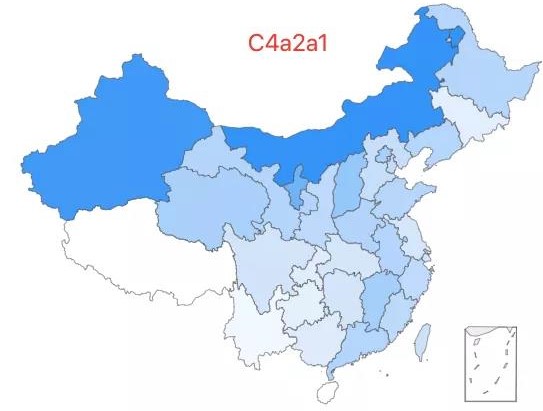
21.「超级祖母 5 号」——C4a2a1 类型,该类型约占中国人口的 0.10%,全国广泛分布,在内蒙古和新疆有较高比例。
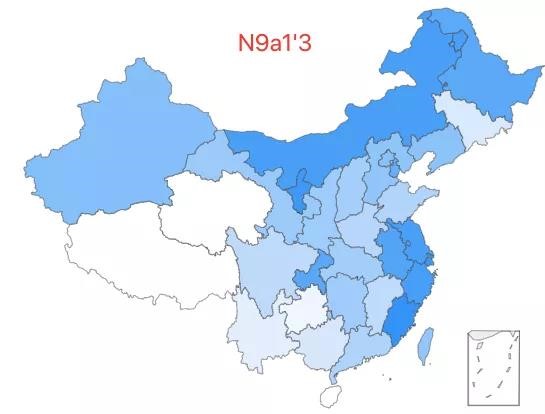
22.「超级祖母 6 号」——N9a1'3 类型,该类型约占中国人口的 0.07%,全国广泛分布,在内蒙古、黑龙江和华东地区有较高比例。
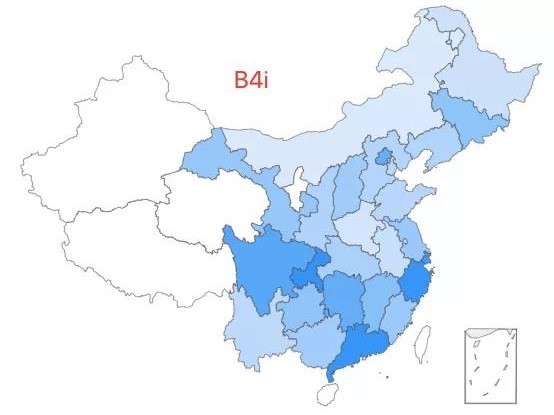
23.「超级祖母 7 号」——B4i 类型,该类型约占中国人口的 0.05%,全国广泛分布,在南方有较高比例。
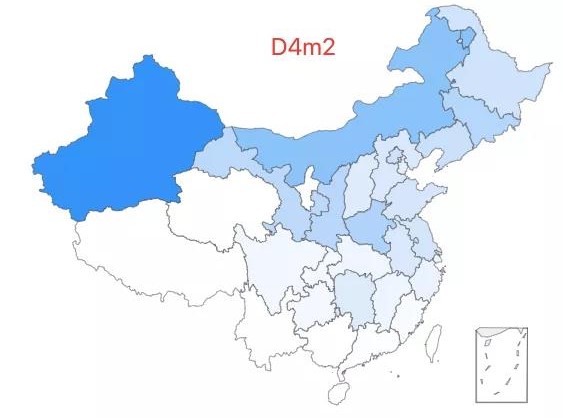
24.「超级祖母 8 号」——D4m2 类型,该类型约占中国人口的 0.07%,全国广泛分布,在新疆和内蒙古有较高比例。
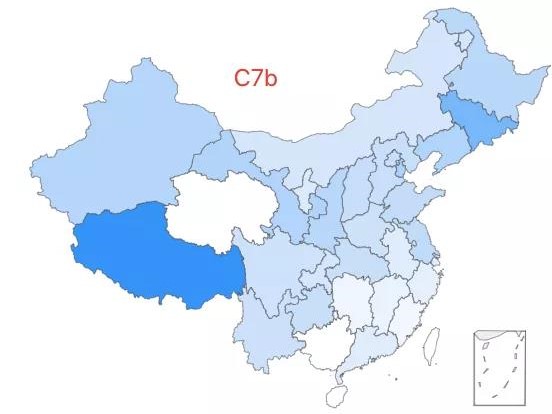
25.「超级祖母 9 号」——C7b 类型,该类型约占中国人口的 0.09%,全国广泛分布,在西藏有较高比例。
附:线粒体单倍群性别构成比例总表