举报该帖子 23魔方检测和微基因检测结果有差异2017-09-20· 4226 浏览20 评论YA yaxin 测了两个公司的 为什么会有比较大的差异 一个是藏缅族群另一个是蒙古语族群 完全南北两方啊 有高人能解释一下吗 谢谢 20 条评论 热门最新 星币国王 2017-09-20你这还不算大的 我见过魔方测出北汉南汉七三开 到了微基因反过来 北汉南汉三七开的8 评论1 赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交 长名字容易让人记住 2017-09-21比如我点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论 星币国王 2017-09-21@长名字容易让人记住:dodecade不打算点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论取消评论 袁 2017-09-25哇你的魔方检测结果和我一样你是哪里的3 评论点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交YA yaxin 2017-09-25爸爸那边是贵州桐梓的 我妈这边是辽宁台安的点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论YA yaxin 2017-09-25有缘哦~点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论取消评论YA yaxin 2017-09-20那这样的话祖源测试有啥意义?这不是忽悠普通人吗 现在到底该相信哪个呢 求解4 评论点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交 Luke 2017-09-20我觉得这个只是由于早期数据样本还不够的原因,应该两家都是。而随着以后越来越多的数据采集和修正应该是会大体接近的,还有包括学术机构的最新研究发现新的活着推翻旧的都有参考价值和影响。毕竟你的数据已经提取出来在那了,而且两家的检测芯片都是一家的,只是相当于分辨率有点区别,一个是60w一个是70w,不同的只是各家的解读和算法。而后面的更新都是基于算法和数据解读方式之类的更新和优化,所以应该会一直更新和修正最后结果的。而你的数据只不过是一个文件只要再导入进去得到一个更接近的值而已。就像比如说(这只是一个比方。。)你的一个地方的数据测出来是112这个数值(两家一样的芯片所以这里是不会有什么特别大的不同的),而目前他们的算法公式是(x+2)*3另外一家的是(x+1.8)*2.8,所以把你的数据导入进去后得到的分别是342和318.64,那么这个对应的就是不同的解读。而之后他们样本数据又更多了于是他们又分别修正出了一个更精确的公式变成了(x+2.5)*2.8和(x+2.1)*2.7,而你的数值112导入进去后出来就成了320.6和308.07,这个数值无疑可能比以前更加精确了,可以得到一些更加微妙的信息在里面,而且两家的也更加接近了。。当然了可能这边又出来一个新的学术论文然后推翻了一些,于是两家的公式又部分推倒修正了结果。但是这些都不影响你已经提取出来的那个112的数值,而只是后期的算法和优化操作了,那边只要系统里重新再把以前的数据重新导入进去这边就更新结果到所有客户端了。。所以基本只要等他们一点一点的修正和采集更多的样本来分析研究解读就可以了。。这个毕竟没有办法急的点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论 Luke 2017-09-20毕竟基因解读这个不像拿到了写软件的源代码,里面都是看得懂有逻辑的语句,只需要根据语法一句一句读出来就能懂了,那么肯定是毫无疑问的一样结果。但是这个更像是软件的逆向破解工程,你可能得到了一堆和乱码无异的数据,需要研究和实验里面出现了那些有特征,重复或者有规律的段落后去解读。而之间的影响也是错综复杂的。。比如说,两个人的只看一个特殊点的特征片段可能是一样的,于是就被分在了同一类。。然后后来研究发现如果那个片段再配上其他一些片段里的信息后就会呈现出不同的意思,于是这两人就有被划分成不同的一类(就像你在大段文字里搜索关键字“是好人”,然后包含这个信息片段的都被黄色高亮了,但其中“不是好人”“小芳是好人妻”“可是好人不多”这些完全不同意思的都被包含进去了)。。大概就是这样的感觉吧。。点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论取消评论 沐绿洲 2017-09-20因为各地分布本来的特征就有差异,没有一个标准答案。比如我去跟另一个人去同一地方抽样调查,结果有差异,当你拿我的结果去定义和别人结果去定义是有差异的。添加评论点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论 东瓯 2017-09-20确实差距挺大的。添加评论点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论 图片关联家族你保存和创建的家族 完成关联单倍群 完成提交评论
星币国王 2017-09-20你这还不算大的 我见过魔方测出北汉南汉七三开 到了微基因反过来 北汉南汉三七开的8 评论1 赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交 长名字容易让人记住 2017-09-21比如我点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论 星币国王 2017-09-21@长名字容易让人记住:dodecade不打算点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论取消评论
袁 2017-09-25哇你的魔方检测结果和我一样你是哪里的3 评论点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交YA yaxin 2017-09-25爸爸那边是贵州桐梓的 我妈这边是辽宁台安的点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论YA yaxin 2017-09-25有缘哦~点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论取消评论
YA yaxin 2017-09-20那这样的话祖源测试有啥意义?这不是忽悠普通人吗 现在到底该相信哪个呢 求解4 评论点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交 Luke 2017-09-20我觉得这个只是由于早期数据样本还不够的原因,应该两家都是。而随着以后越来越多的数据采集和修正应该是会大体接近的,还有包括学术机构的最新研究发现新的活着推翻旧的都有参考价值和影响。毕竟你的数据已经提取出来在那了,而且两家的检测芯片都是一家的,只是相当于分辨率有点区别,一个是60w一个是70w,不同的只是各家的解读和算法。而后面的更新都是基于算法和数据解读方式之类的更新和优化,所以应该会一直更新和修正最后结果的。而你的数据只不过是一个文件只要再导入进去得到一个更接近的值而已。就像比如说(这只是一个比方。。)你的一个地方的数据测出来是112这个数值(两家一样的芯片所以这里是不会有什么特别大的不同的),而目前他们的算法公式是(x+2)*3另外一家的是(x+1.8)*2.8,所以把你的数据导入进去后得到的分别是342和318.64,那么这个对应的就是不同的解读。而之后他们样本数据又更多了于是他们又分别修正出了一个更精确的公式变成了(x+2.5)*2.8和(x+2.1)*2.7,而你的数值112导入进去后出来就成了320.6和308.07,这个数值无疑可能比以前更加精确了,可以得到一些更加微妙的信息在里面,而且两家的也更加接近了。。当然了可能这边又出来一个新的学术论文然后推翻了一些,于是两家的公式又部分推倒修正了结果。但是这些都不影响你已经提取出来的那个112的数值,而只是后期的算法和优化操作了,那边只要系统里重新再把以前的数据重新导入进去这边就更新结果到所有客户端了。。所以基本只要等他们一点一点的修正和采集更多的样本来分析研究解读就可以了。。这个毕竟没有办法急的点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论 Luke 2017-09-20毕竟基因解读这个不像拿到了写软件的源代码,里面都是看得懂有逻辑的语句,只需要根据语法一句一句读出来就能懂了,那么肯定是毫无疑问的一样结果。但是这个更像是软件的逆向破解工程,你可能得到了一堆和乱码无异的数据,需要研究和实验里面出现了那些有特征,重复或者有规律的段落后去解读。而之间的影响也是错综复杂的。。比如说,两个人的只看一个特殊点的特征片段可能是一样的,于是就被分在了同一类。。然后后来研究发现如果那个片段再配上其他一些片段里的信息后就会呈现出不同的意思,于是这两人就有被划分成不同的一类(就像你在大段文字里搜索关键字“是好人”,然后包含这个信息片段的都被黄色高亮了,但其中“不是好人”“小芳是好人妻”“可是好人不多”这些完全不同意思的都被包含进去了)。。大概就是这样的感觉吧。。点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论取消评论
沐绿洲 2017-09-20因为各地分布本来的特征就有差异,没有一个标准答案。比如我去跟另一个人去同一地方抽样调查,结果有差异,当你拿我的结果去定义和别人结果去定义是有差异的。添加评论点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论
东瓯 2017-09-20确实差距挺大的。添加评论点赞 举报该评论 举报该评论 举报类型 违法违规 色情低俗 时政不实信息 引导站外加群 冒充他人 谩骂攻击 网络暴力 其他 无数据 举报描述 举报截图 提交取消评论
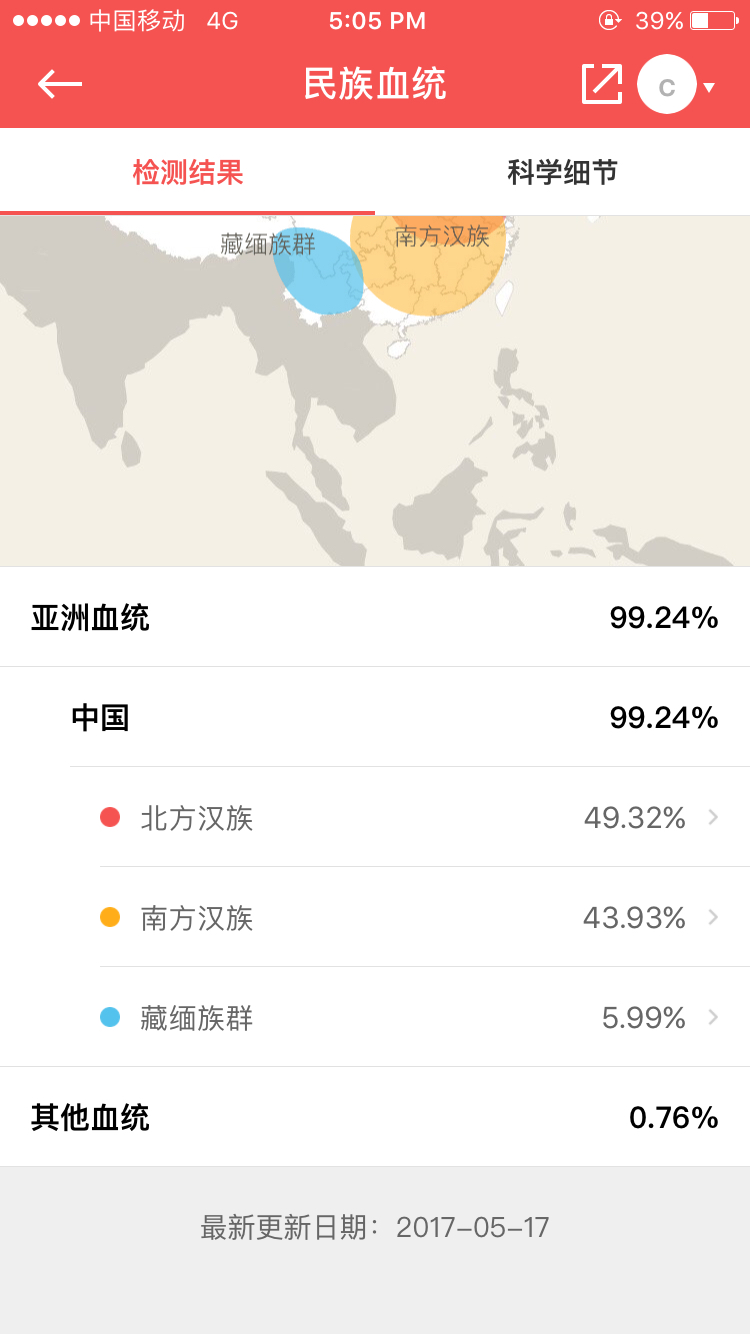
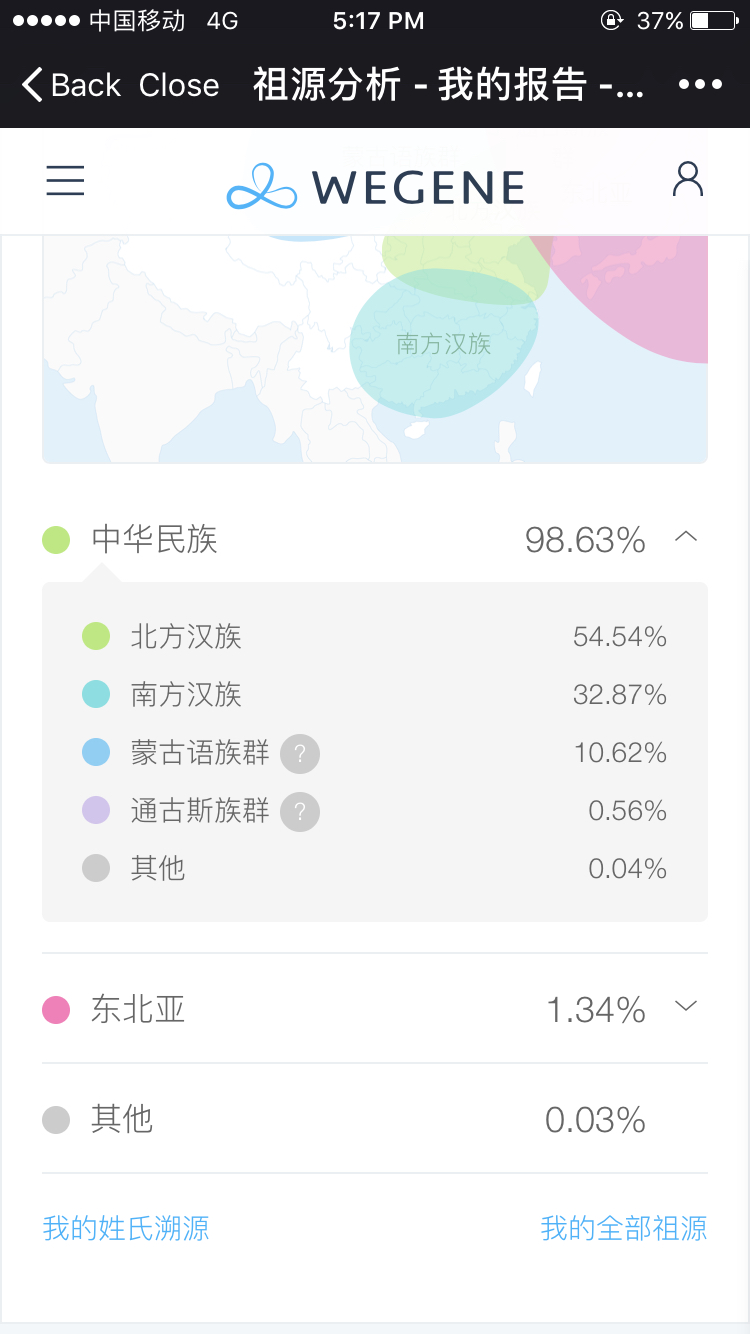 测了两个公司的 为什么会有比较大的差异 一个是藏缅族群另一个是蒙古语族群 完全南北两方啊 有高人能解释一下吗 谢谢测了两个公司的 为什么会有比较大的差异 一个是藏缅族群另一个是蒙古语族群 完全南北两方啊 有高人能解释一下吗 谢谢
测了两个公司的 为什么会有比较大的差异 一个是藏缅族群另一个是蒙古语族群 完全南北两方啊 有高人能解释一下吗 谢谢测了两个公司的 为什么会有比较大的差异 一个是藏缅族群另一个是蒙古语族群 完全南北两方啊 有高人能解释一下吗 谢谢
长名字容易让人记住
点赞
星币国王
点赞