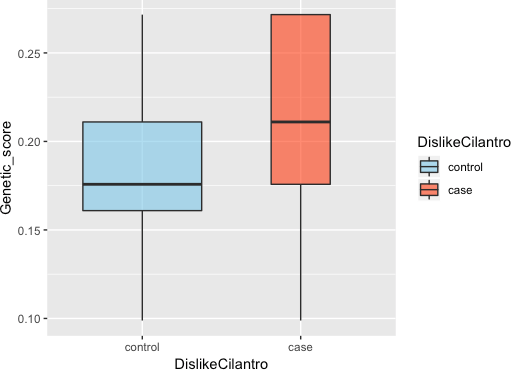
香菜喜好
香菜,学名芫荽,一种调味蔬菜,多用于提味。有人爱之入骨,有人避之不及,但其实,喜不喜欢香菜也可能与基因有关。
检测结果
通过预测模型计算出 3 组基因结果,分段长度代表每组结果的人群占比。
Lv.1
Lv.2
Lv.3
可能性高可能性一般
你喜欢吃香菜的可能性较高
喜欢香菜的人可能有哪些特征?
23魔方研究所的相关研究发现,喜欢香菜的人可能具有如下的一些特征。

香菜喜好与性别
通过对比男女之间喜欢香菜的人群占比,我们发现,相比于女性而言,男性更容易喜欢香菜。* 该结果来自于23魔方研究所,仅基于23魔方的用户样本。

香菜喜好与年龄
我们分析了喜欢和讨厌香菜的两种人群特征,发现喜欢香菜的人年龄偏高。* 该结果来自于23魔方研究所,仅基于23魔方的用户样本。

香菜喜好与榴莲
在分析过程中,我们得出,喜欢榴莲的人往往也更倾向于喜欢香菜,而非讨厌。* 该结果来自于23魔方研究所,仅基于23魔方的用户样本。
为什么有些人是「香菜绝缘体」?
香菜,一种天生具有话题度的食物,有人爱之入骨,而有人却避之不及。同样都是香菜,评价却天差地别,其实是由于个体基因在其中有一些影响。

研究发现,嗅觉相关基因的变异可能会使嗅觉对醛类物质异常敏感。香菜中含有约 40 种化合物,其中 82% 是醛类物质。醛类物质的味道大致可分为两种味道,甜味和肥皂味。因此,在嗅觉上对醛类敏感的人来说,闻到香菜就可能会感觉菜肴像是加了肥皂一般,自然成为了「香菜绝缘体」。
那个小时候不吃香菜的人叛变了
很多人小时候很讨厌吃香菜,饭菜中沾一点香菜味都不行。但长大后,却慢慢喜欢上吃香菜,这是为什么呢?

其实这一现象也和嗅觉有关,有研究表明,嗅觉的敏感度会随着年龄的增长而降低。
小的时候,嗅觉相关基因的变异可能使我们对于醛类物质的「肥皂味」异常敏感,而长大后,由于嗅觉退化的原因,我们对一些刺激性的味道也开始变得宽容,也可能由此「叛变」为喜欢吃香菜。